


随着AI大模型的普及,以及对于工作和生活效率的提高,我们很多个人或者公司也会根据自己业务的需要自行搭建模型。在众多服务商提供的模型中,我们知道 DeepSeek、百度文心一言、阿里通义千问、腾讯混元大模型、华为盘古大模型、字节跳动豆包大模型、智谱 AI 的 ChatGLM 等。大部分的模型服务商都有提供可自定义服务器部署的环境。
在这篇文章中,我们就一起看看如何在亚马逊云EC2服务器中部署阿里云通义千问模型Qwen-7B-Chat。在这里,我们一一梳理整个在亚马逊云EC2服务器部署的过程。在本文中,我们使用的是EC2服务器,如果我们没有的话可以先开通。
亚马逊云EC2开通:亚马逊云EC2免费开通
当然,如果要安装大模型的服务器配置要高,如果我们是基础用途的EC2,在亚马逊有提供免费12个月的t2.micro 实例。
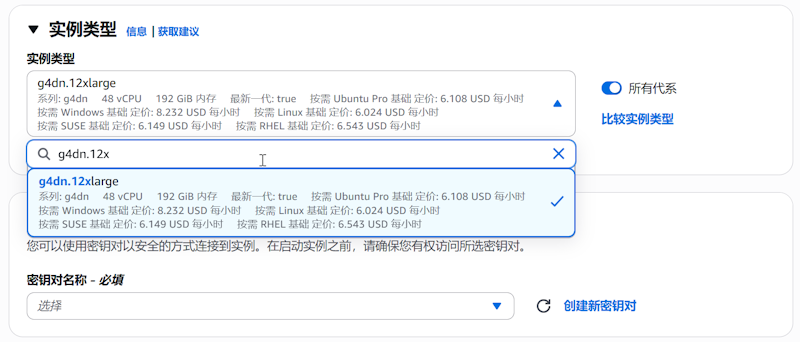
我们在开通EC2服务器的时候,需要选择配置较高的实例,且对应的系统也是有要求的。根据Qwen-7B-Chat大模型的配置要求,至少需要16G内存、100GB的磁盘,所以我们在配置EC2服务器的时候要达到要求,否则你无法运行安装。
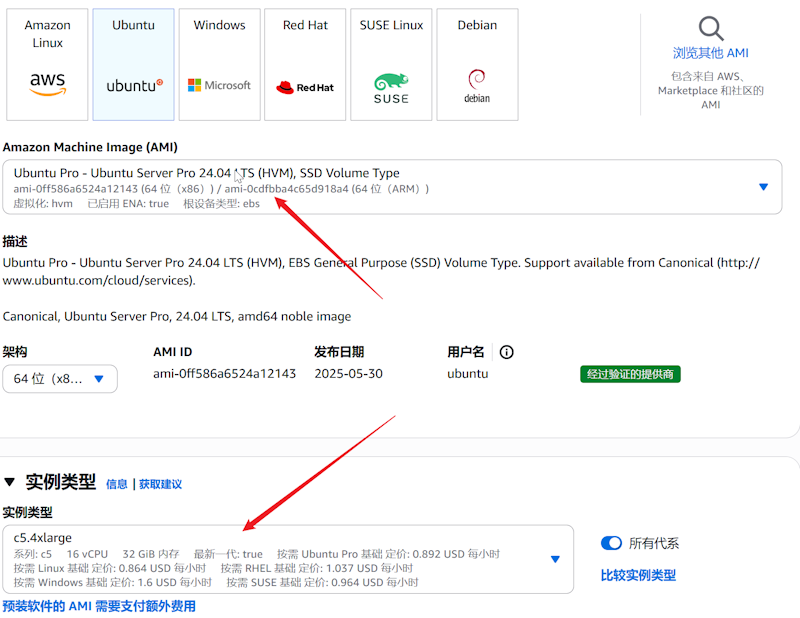
同时在下面的磁盘大小默认是8GB,我们需要增加到100GB。配置EC2服务器的时候,安全组要常规放行,包括要放行一个7860端口,7860端口用于访问WebUI页面。
然后安装并启动Docker容器。且检查容器是否安装。
sudo docker -v
获取并运行Intel xFasterTransformer容器。
sudo docker pull registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23
sudo docker run -it --name xFT -h xFT --privileged --shm-size=16g --network host -v /mnt:/mnt -w /mnt/xFasterTransformer registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23
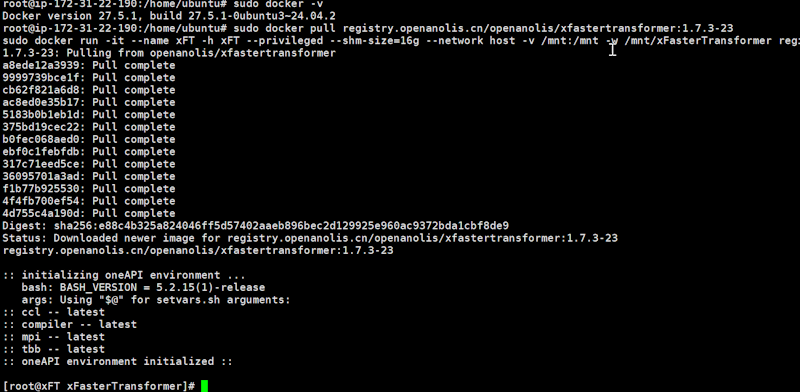
看到如上图的运行结果说明是正确的。
后续操作都需要在容器中运行,如果退出了容器,可以通过以下命令启动并再次进入容器的Shell环境。
sudo docker start xFT
sudo docker exec -it xFT bash
然后我们需要在容器中安装依赖软件。
yum update -y
yum install -y wget git git-lfs vim tmux
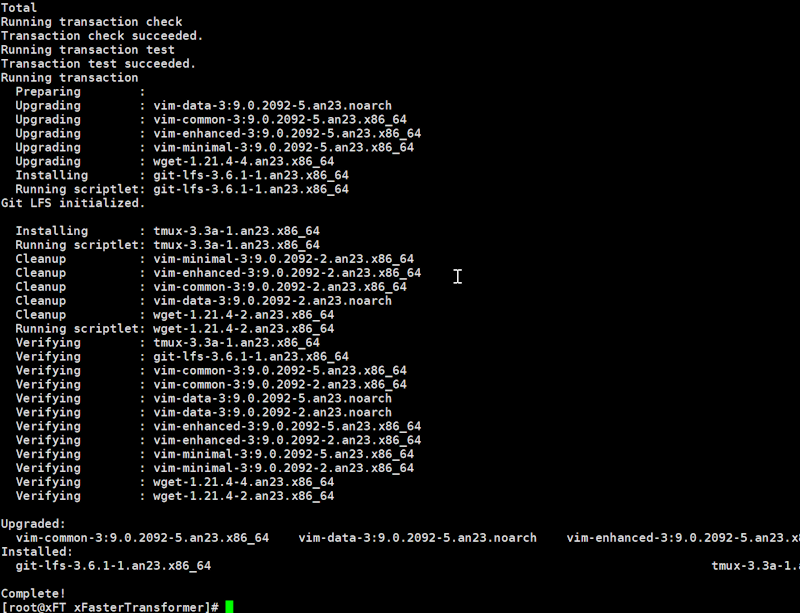
启用Git LFS。
下载预训练模型需要Git LFS的支持。
git lfs install
创建并进入模型数据目录。
mkdir /mnt/data
cd /mnt/data
创建一个tmux session。
tmux
下载Qwen-7B-Chat预训练模型。
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git /mnt/data/qwen-7b-chat
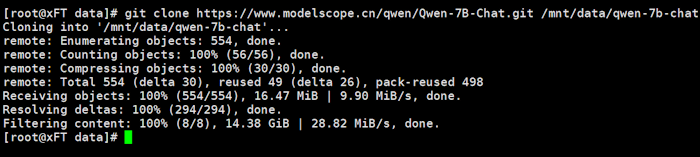
看到如上图的结果说明是正确的,这个过程需要等待几分钟。如果你的磁盘不够大,要求必须60GB以上,否则是不行的。
由于下载的模型数据是HuggingFace格式,需要转换成xFasterTransformer格式。生成的模型文件夹为/mnt/data/qwen-7b-chat-xft。
python -c 'import xfastertransformer as xft; xft.QwenConvert().convert("/mnt/data/qwen-7b-chat")'

看到转换成功。
最后,我们可以运行模型对话。可以用WebUI界面和命名界面。
1、WebUI界面
在容器中,依次执行以下命令,安装WebUI相关依赖软件。
cd /root/xFasterTransformer/examples/web_demo
pip install -r requirements.txt
执行以下命令,升级gradio以避免与fastapi的冲突。
pip install --upgrade gradio
执行以下命令,启动WebUI。
OMP_NUM_THREADS=$(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') / 2)) GRADIO_SERVER_NAME="0.0.0.0" numactl -C $(seq -s, 0 2 $(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') - 2))) -m 0 python Qwen.py -t /mnt/data/qwen-7b-chat -m /mnt/data/qwen-7b-chat-xft -d bf16
如果看到运行成功界面,有一个行出现URL登录WEB的地址,端口是7860,这个端口我们之前有放行的。
2、命令界面
cd /root/xFasterTransformer/examples/pytorch
OMP_NUM_THREADS=$(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') / 2)) LD_PRELOAD=libiomp5.so numactl -C $(seq -s, 0 2 $(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') - 2))) -m 0 python demo.py -t /mnt/data/qwen-7b-chat -m /mnt/data/qwen-7b-chat-xft -d bf16 --chat true
在运行后可以看到命令对话提示。
备注:如果有报错的话,可能是服务器的配置兼容大模型的问题。毕竟对于安装大模型要求的配置还是比较高的,普通云服务器是无法安装的。
原创文章,转载请注明出处:https://www.itbulu.com/qwen-7b-chat.html